We introduce Orchid, a unified latent diffusion model that learns a joint appearance-geometry prior to generate color, depth, and surface normal images in a single diffusion process. This unified approach is more efficient and coherent than current pipelines that use separate models for appearance and geometry. Orchid is versatile - it directly generates color, depth, and normal images from text, supports joint monocular depth and normal estimation with color-conditioned finetuning, and seamlessly inpaints large 3D regions by sampling from the joint distribution. It leverages a novel Variational Autoencoder (VAE) that jointly encodes RGB, relative depth, and surface normals into a shared latent space, combined with a latent diffusion model that denoises these latents. Our extensive experiments demonstrate that Orchid delivers competitive performance against SOTA task-specific methods for geometry prediction, even surpassing them in normal-prediction accuracy and depth-normal consistency. It also inpaints color-depth-normal images jointly, with more qualitative realism than existing multi-step methods.
@inproceedings{OrchidICCV2025,title={{Orchid: Image Latent Diffusion for Joint Appearance and Geometry Generation}},author={Krishnan, Akshay and Yan, Xinchen and Casser, Vincent and Kundu, Abhijit},booktitle={ICCV},year={2025},}
Drive&Gen: Co-Evaluating End-to-End Driving and Video Generation Models
Recent advances in generative models have sparked exciting new possibilities in the field of autonomous vehicles. Specifically, video generation models are now being explored as controllable virtual testing environments. Simultaneously, end-to-end (E2E) driving models have emerged as a streamlined alternative to conventional modular autonomous driving systems, gaining popularity for their simplicity and scalability. However, the application of these techniques to simulation and planning raises important questions. First, while video generation models can generate increasingly realistic videos, can these videos faithfully adhere to the specified conditions and be realistic enough for E2E autonomous planner evaluation? Second, given that data is crucial for understanding and controlling E2E planners, how can we gain deeper insights into their biases and improve their ability to generalize to out-of-distribution scenarios? In this work, we bridge the gap between the driving models and generative world models (Drive&Gen) to address these questions. We propose novel statistical measures leveraging E2E drivers to evaluate the realism of generated videos. By exploiting the controllability of the video generation model, we conduct targeted experiments to investigate distribution gaps affecting E2E planner performance. Finally, we show that synthetic data produced by the video generation model offers a cost-effective alternative to real-world data collection. This synthetic data effectively improves E2E model generalization beyond existing Operational Design Domains, facilitating the expansion of autonomous vehicle services into new operational contexts.
@inproceedings{DriveGenIROS2025,title={{Drive&Gen: Co-Evaluating End-to-End Driving and Video Generation Models}},author={Wang, Jiahao and Yang, Zhenpei and Bai, Yijing and Li, Yingwei and Zou, Yuliang and Sun, Bo and Kundu, Abhijit and Lezama, Jose and Huang, Luna Yue and Zhu, Zehao and Hwang, Jyh-Jing and Anguelov, Dragomir and Tan, Mingxing and Jiang, Chiyu Max},booktitle={IROS},year={2025},}
2024
OmniNOCS: A unified NOCS dataset and model for 3D lifting of 2D objects
We propose OmniNOCS, a large-scale monocular dataset with 3D Normalized Object Coordinate Space (NOCS) maps, object masks, and 3D bounding box annotations for indoor and outdoor scenes. OmniNOCS has 20 times more object classes and 200 times more instances than existing NOCS datasets (NOCS-Real275, Wild6D). We use OmniNOCS to train a novel, transformer-based monocular NOCS prediction model (NOCSformer) that can predict accurate NOCS, instance masks and poses from 2D object detections across diverse classes. It is the first NOCS model that can generalize to a broad range of classes when prompted with 2D boxes. We evaluate our model on the task of 3D oriented bounding box prediction, where it achieves comparable results to state-of-the-art 3D detection methods such as Cube R-CNN. Unlike other 3D detection methods, our model also provides detailed and accurate 3D object shape and segmentation. We propose a novel benchmark for the task of NOCS prediction based on OmniNOCS, which we hope will serve as a useful baseline for future work in this area.
@inproceedings{OmniNOCSECCV2024,title={{OmniNOCS: A unified NOCS dataset and model for 3D lifting of 2D objects}},author={Krishnan, Akshay and Kundu, Abhijit and Maninis, Kevis-Kokitsi and Hays, James and Brown, Matthew},booktitle={ECCV},year={2024},}
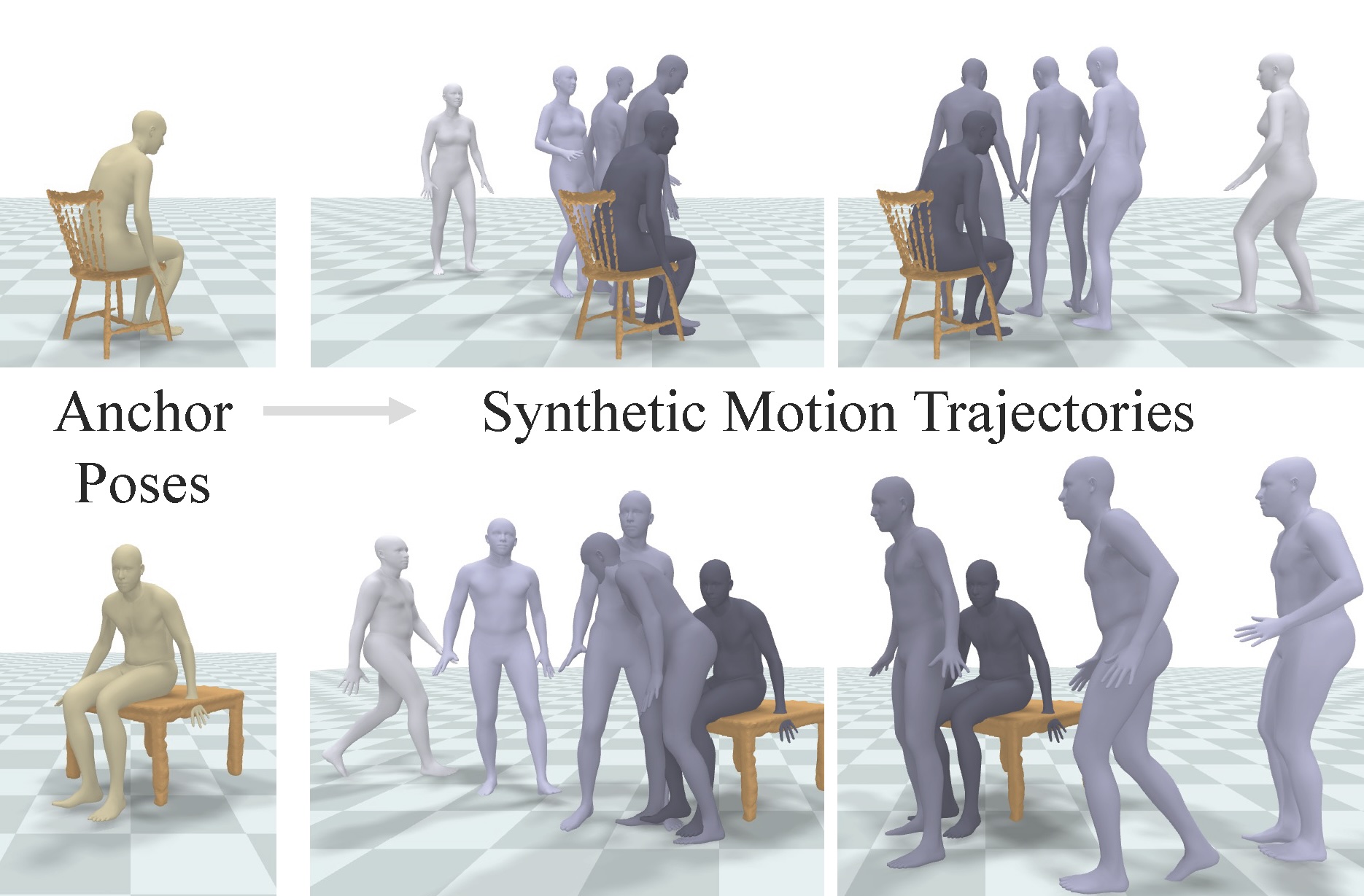
NIFTY: Neural Object Interaction Fields for Guided Human Motion Synthesis
We address the problem of generating realistic 3D motions of humans interacting with objects in a scene. Our key idea is to create a neural interaction field attached to a specific object, which outputs the distance to the valid interaction manifold given a human pose as input. This interaction field guides the sampling of an object-conditioned human motion diffusion model, so as to encourage plausible contacts and affordance semantics. To support interactions with scarcely available data, we propose an automated synthetic data pipeline. For this, we seed a pre-trained motion model, which has priors for the basics of human movement, with interaction-specific anchor poses extracted from limited motion capture data. Using our guided diffusion model trained on generated synthetic data, we synthesize realistic motions for sitting and lifting with several objects, outperforming alternative approaches in terms of motion quality and successful action completion. We call our framework NIFTY: Neural Interaction Fields for Trajectory sYnthesis.
@inproceedings{KulkarniCVPR2024Nifty,title={{NIFTY: Neural Object Interaction Fields for Guided Human Motion Synthesis}},author={Kulkarni, Nilesh and Rempe, Davis and Genova, Kyle and Kundu, Abhijit and Johnson, Justin and Fouhey, David and Guibas, Leonidas},booktitle={CVPR},year={2024},}
NeRFMeshing: Distilling Neural Radiance Fields into Geometrically-Accurate 3D Meshes
With the introduction of Neural Radiance Fields (NeRFs), novel view synthesis has recently made a big leap forward. At the core, NeRF proposes that each 3D point can emit radiance, allowing to conduct view synthesis using differentiable volumetric rendering. While neural radiance fields can accurately represent 3D scenes for computing the image rendering, 3D meshes are still the main scene representation supported by most computer graphics and simulation pipelines, enabling tasks such as real time rendering and physics-based simulations. Obtaining 3D meshes from neural radiance fields still remains an open challenge since NeRFs are optimized for view synthesis, not enforcing an accurate underlying geometry on the radiance field. We thus propose a novel compact and flexible architecture that enables easy 3D surface reconstruction from any NeRF-driven approach. Upon having trained the radiance field, we distill the volumetric 3D representation into a Signed Surface Approximation Network, allowing easy extraction of the 3D mesh and appearance. Our final 3D mesh is physically accurate and can be rendered in real time on an array of devices.
@inproceedings{NeRFMeshing3DV2024,title={{NeRFMeshing: Distilling Neural Radiance Fields into Geometrically-Accurate 3D Meshes}},author={Rakotosaona, Marie-Julie and Manhardt, Fabian and Arroyo, Diego Martin and Niemeyer, Michael and Kundu, Abhijit and Tombari, Federico},booktitle={3DV},year={2024},}
2023
Nerflets: Local Radiance Fields for Efficient Structure-Aware 3D Scene Representation from 2D Supervision
We address efficient and structure-aware 3D scene representation from images. Nerflets are our key contribution – a set of local neural radiance fields that together represent a scene. Each nerflet maintains its own spatial position, orientation, and extent, within which it contributes to panoptic, density, and radiance reconstructions. By leveraging only photometric and inferred panoptic image supervision, we can directly and jointly optimize the parameters of a set of nerflets so as to form a decomposed representation of the scene, where each object instance is represented by a group of nerflets. During experiments with indoor and outdoor environments, we find that nerflets: (1) fit and approximate the scene more efficiently than traditional global NeRFs, (2) allow the extraction of panoptic and photometric renderings from arbitrary views, and (3) enable tasks rare for NeRFs, such as 3D panoptic segmentation and interactive editing.
@inproceedings{ZhangCVPR2023Nerflets,title={{Nerflets: Local Radiance Fields for Efficient Structure-Aware 3D Scene Representation from 2D Supervision}},author={Zhang, Xiaoshuai and Kundu, Abhijit and Funkhouser, Thomas and Guibas, Leonidas and Su, Hao and Genova, Kyle},booktitle={CVPR},year={2023},}
Neural Radiance Fields (NeRFs) have emerged as a powerful neural 3D representation for objects and scenes derived from 2D data. Generating NeRFs, however, remains difficult in many scenarios. For instance, training a NeRF with only a small number of views as supervision remains challenging since it is an under-constrained problem. In such settings, it calls for some inductive prior to filter out bad local minima. One way to introduce such inductive priors is to learn a generative model for NeRFs modeling a certain class of scenes. In this paper, we propose to use a diffusion model to generate NeRFs encoded on a regularized grid. We show that our model can sample realistic NeRFs, while at the same time allowing conditional generations, given a certain observation as guidance.
@inproceedings{NFDiffusionICLR2023,title={{Learning a Diffusion Prior for NeRFs}},author={Yang, Guandao and Kundu, Abhijit and Guibas, Leonidas and Barron, Jonathan T. and Poole, Ben},booktitle={ICLR Workshop},year={2023},}
2022
Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation
We present Panoptic Neural Fields (PNF), an object-aware neural scene representation that decomposes a scene into a set of objects (things) and background (stuff). Each object is represented by an oriented 3D bounding box and a multi-layer perceptron (MLP) that takes position, direction, and time and outputs density and radiance. The background stuff is represented by a similar MLP that additionally outputs semantic labels. Each object MLPs are instance-specific and thus can be smaller and faster than previous object-aware approaches, while still leveraging category-specific priors incorporated via meta-learned initialization. Our model builds a panoptic radiance field representation of any scene from just color images. We use off-the-shelf algorithms to predict camera poses, object tracks, and 2D image semantic segmentations. Then we jointly optimize the MLP weights and bounding box parameters using analysis-by-synthesis with self-supervision from color images and pseudo-supervision from predicted semantic segmentations. During experiments with real-world dynamic scenes, we find that our model can be used effectively for several tasks like novel view synthesis, 2D panoptic segmentation, 3D scene editing, and multiview depth prediction.
@inproceedings{KunduCVPR2022PNF,title={{Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation}},author={Kundu, Abhijit and Genova, Kyle and Yin, Xiaoqi and Fathi, Alireza and Pantofaru, Caroline and Guibas, Leonidas and Tagliasacchi, Andrea and Dellaert, Frank and Funkhouser, Thomas},booktitle={CVPR},year={2022},}
Kubric: A scalable dataset generator
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, Thomas Kipf,
Abhijit Kundu, Dmitry Lagun, Issam Laradji, Hsueh-Ti (Derek) Liu, Henning Meyer, Yishu Miao, Derek Nowrouzezahrai, Cengiz Oztireli, Etienne Pot, Noha Radwan, Daniel Rebain, Sara Sabour, Mehdi S. M. Sajjadi, Matan Sela, Vincent Sitzmann, Austin Stone, Deqing Sun, Suhani Vora, Ziyu Wang, Tianhao Wu, Kwang Moo Yi, Fangcheng Zhong, Andrea Tagliasacchi.
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification..
@inproceedings{KubricCVPR2022,author={Greff, Klaus and Belletti, Francois and Beyer, Lucas and Doersch, Carl and Du, Yilun and Duckworth, Daniel and Fleet, David J and Gnanapragasam, Dan and Golemo, Florian and Herrmann, Charles and Kipf, Thomas and Kundu, Abhijit and Lagun, Dmitry and Laradji, Issam and Liu, Hsueh-Ti (Derek) and Meyer, Henning and Miao, Yishu and Nowrouzezahrai, Derek and Oztireli, Cengiz and Pot, Etienne and Radwan, Noha and Rebain, Daniel and Sabour, Sara and Sajjadi, Mehdi S. M. and Sela, Matan and Sitzmann, Vincent and Stone, Austin and Sun, Deqing and Vora, Suhani and Wang, Ziyu and Wu, Tianhao and Yi, Kwang Moo and Zhong, Fangcheng and Tagliasacchi, Andrea},title={Kubric: A scalable dataset generator},booktitle={CVPR},year={2022},}
im2nerf: Image to Neural Radiance Field in the Wild
We propose im2nerf, a learning framework that predicts a continuous neural object representation given a single input image in the wild, supervised by only segmentation output from off-the-shelf recognition methods. The standard approach to constructing neural radiance fields takes advantage of multi-view consistency and requires many calibrated views of a scene, a requirement that cannot be satisfied when learning on large-scale image data in the wild. We take a step towards addressing this shortcoming by introducing a model that encodes the input image into a disentangled object representation that contains a code for object shape, a code for object appearance, and an estimated camera pose from which the object image is captured. Our model conditions a NeRF on the predicted object representation and uses volume rendering to generate images from novel views. We train the model end-to-end on a large collection of input images. As the model is only provided with single-view images, the problem is highly under-constrained. Therefore, in addition to using a reconstruction loss on the synthesized input view, we use an auxiliary adversarial loss on the novel rendered views. Furthermore, we leverage object symmetry and cycle camera pose consistency. We conduct extensive quantitative and qualitative experiments on the ShapeNet dataset as well as qualitative experiments on Open Images dataset. We show that in all cases, im2nerf achieves the state-of-the-art performance for novel view synthesis from a single-view unposed image in the wild.
@article{Mi2022im2nerf,title={{im2nerf: Image to Neural Radiance Field in the Wild}},author={Mi, Lu and Kundu, Abhijit and Ross, David and Dellaert, Frank and Snavely, Noah and Fathi, Alireza},year={2022},}
2021
Semantic Segmentation with only 2D Image Supervision
With the recent growth of urban mapping and autonomous driving efforts, there has been an explosion of raw 3D data collected from terrestrial platforms with lidar scanners and color cameras. However, due to high labeling costs, ground-truth 3D semantic segmentation annotations are limited in both quantity and geographic diversity, while also being difficult to transfer across sensors. In contrast, large image collections with ground-truth semantic segmentations are readily available for diverse sets of scenes. In this paper, we investigate how to use only those labeled 2D image collections to supervise training 3D semantic segmentation models. Our approach is to train a 3D model from pseudo-labels derived from 2D semantic image segmentations using multiview fusion. We address several novel issues with this approach, including how to select trusted pseudo-labels, how to sample 3D scenes with rare object categories, and how to decouple input features from 2D images from pseudo-labels during training. The proposed network architecture, 2D3DNet, achieves significantly better performance (+6.2-11.4 mIoU) than baselines during experiments on a new urban dataset with lidar and images captured in 20 cities across 5 continents.
@inproceedings{2D3DNet3DV2021,title={Semantic Segmentation with only 2D Image Supervision},author={Genova, Kyle and Yin, Xiaoqi and Kundu, Abhijit and Pantofaru, Caroline and Cole, Forrester and Sud, Avneesh and Brewington, Brian and Shucker, Brian and Funkhouser, Thomas},booktitle={3DV},year={2021},}
2020
Virtual Multi-view Fusion for 3D Semantic Segmentation
Semantic segmentation of 3D meshes is an important problem for 3D scene understanding. In this paper we revisit the classic multiview representation of 3D meshes and study several techniques that make them effective for 3D semantic segmentation of meshes. Given a 3D mesh reconstructed from RGBD sensors, our method effectively chooses different virtual views of the 3D mesh and renders multiple 2D channels for training an effective 2D semantic segmentation model. Features from multiple per view predictions are finally fused on 3D mesh vertices to predict mesh semantic segmentation labels. Using the large scale indoor 3D semantic segmentation benchmark of ScanNet, we show that our virtual views enable more effective training of 2D semantic segmentation networks than previous multiview approaches. When the 2D per pixel predictions are aggregated on 3D surfaces, our virtual multiview fusion method is able to achieve significantly better 3D semantic segmentation results compared to all prior multiview approaches and recent 3D convolution approaches.
@inproceedings{KunduECCV2020VirtualMVFusion,title={Virtual Multi-view Fusion for 3D Semantic Segmentation},author={Kundu, Abhijit and Yin, Xiaoqi and Fathi, Alireza and Ross, David and Brewington, Brian and Funkhouser, Thomas and Pantofaru, Caroline},booktitle={ECCV},year={2020},doi={10.1007/978-3-030-58586-0_31},url={https://doi.org/10.1007/978-3-030-58586-0_31},isbn={978-3-030-58586-0},}
Pillar-based Object Detection for Autonomous Driving
We present a simple and flexible object detection framework optimized for autonomous driving. Building on the observation that point clouds in this application are extremely sparse, we propose a practical pillar-based approach to fix the imbalance issue caused by anchors. In particular, our algorithm incorporates a cylindrical projection into multi-view feature learning, predicts bounding box parameters per pillar rather than per point or per anchor, and includes an aligned pillar-to-point projection module to improve the final prediction. Our anchor-free approach avoids hyperparameter search associated with past methods, simplifying 3D object detection while significantly improving upon state-of-the-art.
@inproceedings{WangECCV2020,author={Wang, Yue and Fathi, Alireza and Kundu, Abhijit and Ross, David and Pantofaru, Caroline and Funkhouser, Thomas and Solomon, Justin},title={Pillar-based Object Detection for Autonomous Driving},booktitle={ECCV},year={2020},doi={10.1007/978-3-030-58542-6_2},url={https://doi.org/10.1007/978-3-030-58542-6_2},}
An LSTM Approach to Temporal 3D Object Detection in LiDAR Point Clouds
Detecting objects in 3D LiDAR data is a core technology for autonomous driving and other robotics applications. Although LiDAR data is acquired over time, most of the 3D object detection algorithms propose object bounding boxes independently for each frame and neglect the useful information available in the temporal domain. To address this problem, in this paper we propose a sparse LSTM-based multi-frame 3d object detection algorithm. We use a U-Net style 3D sparse convolution network to extract features for each frame’s LiDAR point-cloud. These features are fed to the LSTM module together with the hidden and memory features from last frame to predict the 3d objects in the current frame as well as hidden and memory features that are passed to the next frame. Experiments on the Waymo Open Dataset show that our algorithm outperforms the traditional frame by frame approach by 7.5% mAP@0.7 and other multi-frame approaches by 1.2% while using less memory and computation per frame. To the best of our knowledge, this is the first work to use an LSTM for 3D object detection in sparse point clouds.
@inproceedings{HuangECCV2020,author={Huang, Rui and Zhang, Wanyue and Funkhouser, Thomas and Kundu, Abhijit and Pantofaru, Caroline and Ross, David and Fathi, Alireza},title={An LSTM Approach to Temporal 3D Object Detection in LiDAR Point Clouds},booktitle={ECCV},year={2020},doi={10.1007/978-3-030-58523-5_16},url={https://doi.org/10.1007/978-3-030-58523-5_16},video={https://www.youtube.com/watch?v=5M2cbMbBJ2U},}
Realistic color texture generation is an important step in RGB-D surface reconstruction, but remains challenging in practice due to inaccuracies in reconstructed geometry, misaligned camera poses, and view-dependent imaging artifacts. In this work, we present a novel approach for color texture generation using a conditional adversarial loss obtained from weakly-supervised views. Specifically, we propose an approach to produce photorealistic textures for approximate surfaces, even from misaligned images, by learning an objective function that is robust to these errors. The key idea of our approach is to learn a patch-based conditional discriminator which guides the texture optimization to be tolerant to misalignments. Our discriminator takes a synthesized view and a real image, and evaluates whether the synthesized one is realistic, under a broadened definition of realism. We train the discriminator by providing as ‘real’ examples pairs of input views and their misaligned versions – so that the learned adversarial loss will tolerate errors from the scans. Experiments on synthetic and real data under quantitative or qualitative evaluation demonstrate the advantage of our approach in comparison to state of the art. Our code is publicly available with video demonstration.
@inproceedings{HuangCVPR2020,author={Huang, Jingwei and Thies, Justus and Dai, Angela and Kundu, Abhijit and Jiang, Chiyu Max and Guibas, Leonidas and Nießner, Matthias and Funkhouser, Thomas},title={Adversarial Texture Optimization from RGB-D Scans},booktitle={CVPR},year={2020},doi={10.1109/CVPR42600.2020.00163},url={https://doi.org/10.1109/CVPR42600.2020.00163},video={https://www.youtube.com/watch?v=52xlRn0ESek},}
DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes
We propose DOPS, a fast single-stage 3D object detection method for LIDAR data. Previous methods often make domain-specific design decisions, for example projecting points into a bird-eye view image in autonomous driving scenarios. In contrast, we propose a general-purpose method that works on both indoor and outdoor scenes. The core novelty of our method is a fast, single-pass architecture that both detects objects in 3D and estimates their shapes. 3D bounding box parameters are estimated in one pass for every point, aggregated through graph convolutions, and fed into a branch of the network that predicts latent codes representing the shape of each detected object. The latent shape space and shape decoder are learned on a synthetic dataset and then used as supervision for the end-to-end training of the 3D object detection pipeline. Thus our model is able to extract shapes without access to ground-truth shape information in the target dataset. During experiments, we find that our proposed method achieves state-of-the-art results by 5% on object detection in ScanNet scenes, and it gets top results by 3.4% in the Waymo Open Dataset, while reproducing the shapes of detected cars.
@inproceedings{NajibiCVPR2020,author={Najibi, Mahyar and Lai, Guangda and Kundu, Abhijit and Lu, Zhichao and Rathod, Vivek and Funkhouser, Thomas and Pantofaru, Caroline and Ross, David and Davis, Larry S. and Fathi, Alireza},title={DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes},booktitle={CVPR},year={2020},doi={10.1109/CVPR42600.2020.01193},url={https://doi.org/10.1109/CVPR42600.2020.01193},video={https://www.youtube.com/watch?v=8UWqxqnXCyo},}
2018
3D-RCNN: Instance-level 3D Object Reconstruction via Render-and-Compare
We present a fast inverse-graphics framework for instance-level 3D scene understanding. We train a deep convolutional network that learns to map image regions to the full 3D shape and pose of all object instances in the image. Our method produces a compact 3D representation of the scene, which can be readily used for applications like autonomous driving. Many traditional 2D vision outputs, like instance segmentations and depth-maps, can be obtained by simply rendering our output 3D scene model. We exploit class-specific shape priors by learning a low dimensional shape-space from collections of CAD models. We present novel representations of shape and pose, that strive towards better 3D equivariance and generalization. In order to exploit rich supervisory signals in the form of 2D annotations like segmentation, we propose a differentiable Render-and-Compare loss that allows 3D shape and pose to be learned with 2D supervision. We evaluate our method on the challenging real-world datasets of Pascal3D+ and KITTI, where we achieve state-of-the-art results.
@inproceedings{3DRCNN_CVPR2018,author={Kundu, Abhijit and Li, Yin and Rehg, James M.},title={3D-RCNN: Instance-level 3D Object Reconstruction via Render-and-Compare},booktitle={CVPR},year={2018},doi={10.1109/CVPR.2018.00375},url={https://doi.org/10.1109/CVPR.2018.00375},}
2017
Visual 3D Tracking of Child-Adult Social Interactions
We describe an approach to continuously capture children’s 3D head pose and location during a tabletop social interaction with an adult examiner. Our approach, called face plus context, utilizes a fixed room camera in conjunction with a head-worn camera on the examiner to simultaneously capture the child’s face along with the toys and social partners that provide context. Our system performs head tracking and pose estimation along with multi-target tracking to provide 3D localization and disambiguate identity. We evaluated our method on a dataset of 16 children, including both typically developing and autistic children. We present encouraging results for measuring children’s social behaviors, along with validation results using an IMU.
@inproceedings{ChongICDL2017,author={Chong, Eunji and Southerland, Audrey and Kundu, Abhijit and Jones, Rebecca M and Rozga, Agata and Rehg, James M.},title={Visual 3D Tracking of Child-Adult Social Interactions},booktitle={CVPR},year={2017},doi={10.1109/DEVLRN.2017.8329835},url={https://doi.org/10.1109/DEVLRN.2017.8329835},}
2016
Feature Space Optimization for Semantic Video Segmentation
We present an approach to long-range spatio-temporal regularization in semantic video segmentation. Temporal regularization in video is challenging because both the camera and the scene may be in motion. Thus Euclidean distance in the space-time volume is not a good proxy for correspondence. We optimize the mapping of pixels to a Euclidean feature space so as to minimize distances between corresponding points. Structured prediction is performed by a dense CRF that operates on the optimized features. Experimental results demonstrate that the presented approach increases the accuracy and temporal consistency of semantic video segmentation.
@inproceedings{KunduCVPR2016VideoFSO,title={Feature Space Optimization for Semantic Video Segmentation},author={Kundu, Abhijit and Vineet, Vibhav and Koltun, Vladlen},booktitle={CVPR},year={2016},doi={10.1109/CVPR.2016.345},url={https://doi.org/10.1109/CVPR.2016.345},}
2015
Multi-scale perception and path planning on probabilistic obstacle maps
We present a path-planning algorithm that leverages a multi-scale representation of the environment. The algorithm works in n dimensions. The information of the environment is stored in a tree representing a recursive dyadic partitioning of the search space. The information used by the algorithm is the probability that a node of the tree corresponds to an obstacle in the search space. The complexity of the proposed algorithm is analyzed and its completeness is shown.
@inproceedings{HauerICRA2015,title={Multi-scale perception and path planning on probabilistic obstacle maps},author={Hauer, Florian and Kundu, Abhijit and Rehg, James M. and Tsiotras, Panagiotis},booktitle={ICRA},year={2015},doi={10.1109/ICRA.2015.7139779},url={https://doi.org/10.1109/ICRA.2015.7139779},}
2014
Joint Semantic Segmentation and 3D Reconstruction from Monocular Video
We present an approach for joint inference of 3D scene structure and semantic labeling for monocular video. Starting with monocular image stream, our framework produces a 3D volumetric semantic + occupancy map, which is much more useful than a series of 2D semantic label images or a sparse point cloud produced by traditional semantic segmentation and Structure from Motion(SfM) pipelines respectively. We derive a Conditional Random Field (CRF) model defined in the 3D space, that jointly infers the semantic category and occupancy for each voxel. Such a joint inference in the 3D CRF paves the way for more informed priors and constraints, which is otherwise not possible if solved separately in their traditional frameworks. We make use of class specific semantic cues that constrain the 3D structure in areas, where multiview constraints are weak. Our model comprises of higher order factors, which helps when the depth is unobservable.We also make use of class specific semantic cues to reduce either the degree of such higher order factors, or to approximately model them with unaries if possible. We demonstrate improved 3D structure and temporally consistent semantic segmentation for difficult, large scale, forward moving monocular image sequences.
@inproceedings{KunduECCV2014JointSegRec,title={Joint Semantic Segmentation and 3D Reconstruction from Monocular Video},author={Kundu, Abhijit and Li, Yin and Dellaert, Frank and Li, Fuxin and Rehg, James M.},booktitle={ECCV},year={2014},doi={10.1007/978-3-319-10599-4_45},url={https://doi.org/10.1007/978-3-319-10599-4_45},isbn={978-3-319-10599-4},}
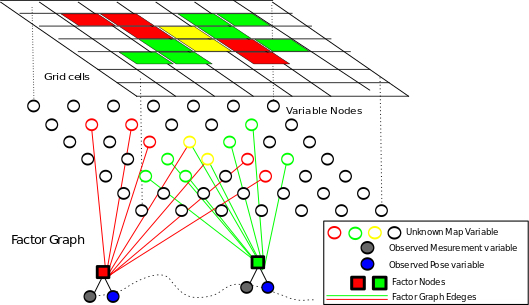
Modern MAP inference methods for accurate and fast occupancy grid mapping on higher order factor graphs
Using the inverse sensor model has been popular in occupancy grid mapping. However, it is widely known that applying the inverse sensor model to mapping requires certain assumptions that are not necessarily true. Even the works that use forward sensor models have relied on methods like expectation maximization or Gibbs sampling which have been succeeded by more effective methods of maximum a posteriori (MAP) inference over graphical models. In this paper, we propose the use of modern MAP inference methods along with the forward sensor model. Our implementation and experimental results demonstrate that these modern inference methods deliver more accurate maps more efficiently than previously used methods.
@inproceedings{DhimanICRA2014,title={Modern MAP inference methods for accurate and fast occupancy grid mapping on higher order factor graphs},author={Dhiman, Vikas and Kundu, Abhijit and Dellaert, Frank and Corso, Jason J.},booktitle={ICRA},year={2014},doi={10.1109/ICRA.2014.6907129},url={https://doi.org/10.1109/ICRA.2014.6907129},}
2012
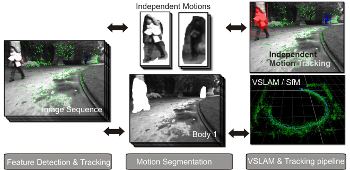
Motion Segmentation of Multiple Objects from a Freely Moving Monocular Camera
Motion segmentation is an inevitable component for mobile robotic systems such as the case with robots performing SLAM and collision avoidance in dynamic worlds. This paper proposes an incremental motion segmentation system that efficiently segments multiple moving objects and simultaneously build the map of the environment using visual SLAM modules. Multiple cues based on optical flow and two view geometry are integrated to achieve this segmentation. A dense optical flow algorithm is used for dense tracking of features. Motion potentials based on geometry are computed for each of these dense tracks. These geometric potentials along with the optical flow potentials are used to form a graph like structure. A graph based segmentation algorithm then clusters together nodes of similar potentials to form the eventual motion segments. Experimental results of high quality segmentation on different publicly available datasets demonstrate the effectiveness of our method.
@inproceedings{NamdevICRA2012,title={Motion Segmentation of Multiple Objects from a Freely Moving Monocular Camera},author={Namdev, Rahul and Kundu, Abhijit and Krishna, K. M. and Jawahar, C. V.},booktitle={ICRA},year={2012},doi={10.1109/ICRA.2012.6224800},url={https://doi.org/10.1109/ICRA.2012.6224800},}
2011
Realtime Multibody Visual SLAM with a Smoothly Moving Monocular Camera
This paper presents a realtime, incremental multibody visual SLAM system that allows choosing between full 3D reconstruction or simply tracking of the moving objects. Motion reconstruction of dynamic points or objects from a monocular camera is considered very hard due to well known problems of observability. We attempt to solve the problem with a Bearing only Tracking (BOT) and by integrating multiple cues to avoid observability issues. The BOT is accomplished through a particle filter, and by integrating multiple cues from the reconstruction pipeline. With the help of these cues, many real world scenarios which are considered unobservable with a monocular camera is solved to reasonable accuracy. This enables building of a unified dynamic 3D map of scenes involving multiple moving objects. Tracking and reconstruction is preceded by motion segmentation and detection which makes use of efficient geometric constraints to avoid difficult degenerate motions, where objects move in the epipolar plane. Results reported on multiple challenging real world image sequences verify the efficacy of the proposed framework.
@inproceedings{KunduICCV2011,title={Realtime Multibody Visual SLAM with a Smoothly Moving Monocular Camera},author={Kundu, Abhijit and Krishna, K. M. and Jawahar, C. V.},booktitle={ICCV},year={2011},doi={10.1109/ICCV.2011.6126482},url={https://doi.org/10.1109/ICCV.2011.6126482},}
2010
Realtime Motion Segmentation based Multibody Visual SLAM
Motion segmentation is an inevitable component for mobile robotic systems such as the case with robots performing SLAM and collision avoidance in dynamic worlds. This paper proposes an incremental motion segmentation system that efficiently segments multiple moving objects and simultaneously build the map of the environment using visual SLAM modules. Multiple cues based on optical flow and two view geometry are integrated to achieve this segmentation. A dense optical flow algorithm is used for dense tracking of features. Motion potentials based on geometry are computed for each of these dense tracks. These geometric potentials along with the optical flow potentials are used to form a graph like structure. A graph based segmentation algorithm then clusters together nodes of similar potentials to form the eventual motion segments. Experimental results of high quality segmentation on different publicly available datasets demonstrate the effectiveness of our method.
@inproceedings{KunduICVGIP2010,title={Realtime Motion Segmentation based Multibody Visual SLAM},author={Kundu, Abhijit and Krishna, K. M. and Jawahar, C. V.},booktitle={ICVGIP},year={2010},doi={10.1145/1924559.1924593},url={http://doi.acm.org/10.1145/1924559.1924593},}
Realtime Moving Object Detection from a Freely moving Monocular Camera
Detection of moving objects is a key component in mobile robotic perception and understanding of the environment. In this paper, we describe a realtime independent motion detection algorithm for this purpose. The method is robust and is capable of detecting difficult degenerate motions, where the moving objects is followed by a moving camera in the same direction. This robustness is attributed to the use of efficient geometric constraints and a probability framework which propagates the uncertainty in the system. The proposed independent motion detection framework integrates seamlessly with existing visual SLAM solutions. The system consists of multiple modules which are tightly coupled so that one module benefits from another. The integrated system can simultaneously detect multiple moving objects in realtime from a freely moving monocular camera.
@inproceedings{KunduROBIO2010,title={Realtime Moving Object Detection from a Freely moving Monocular Camera},author={Kundu, Abhijit and Jawahar, C. V. and Krishna, K. M.},booktitle={ROBIO},year={2010},doi={10.1109/ROBIO.2010.5723575},url={http://doi.acm.org/10.1109/ROBIO.2010.5723575},}
2009
Moving Object Detection by Multi-View Geometric Techniques from a Single Camera Mounted Robot
The ability to detect, and track multiple moving objects like person and other robots, is an important prerequisite for mobile robots working in dynamic indoor environments. We approach this problem by detecting independently moving objects in image sequence from a monocular camera mounted on a robot. We use multi-view geometric constraints to classify a pixel as moving or static. The first constraint, we use, is the epipolar constraint which requires images of static points to lie on the corresponding epipolar lines in subsequent images. In the second constraint, we use the knowledge of the robot motion to estimate a bound in the position of image pixel along the epipolar line. This is capable of detecting moving objects followed by a moving camera in the same direction, a so-called degenerate configuration where the epipolar constraint fails. To classify the moving pixels robustly, a Bayesian framework is used to assign a probability that the pixel is stationary or dynamic based on the above geometric properties and the probabilities are updated when the pixels are tracked in subsequent images. The same framework also accounts for the error in estimation of camera motion. Successful and repeatable detection and pursuit of people and other moving objects in realtime with a monocular camera mounted on the Pioneer 3DX, in a cluttered environment confirms the efficacy of the method.
@inproceedings{KunduIROS2009,title={Moving Object Detection by Multi-View Geometric Techniques from a Single Camera Mounted Robot},author={Kundu, Abhijit and Krishna, K. M. and Sivaswamy, J.},booktitle={IROS},year={2009},doi={10.1109/IROS.2009.5354227},url={http://doi.acm.org/10.1109/IROS.2009.5354227},}